?인턴을 시작한 지 어느덧 두 달이 넘어갔다. 오늘은 그동안 공부한 내용들과 분석한 내용을 바탕으로 '캠퍼스론을 위한 데이터 정형화 프로젝트'에서 진행하고 있는 내용에 대해서 이야기해 보려고한다.
개발일지1
우선 어떤 특정한 주제를 정해서 그 내용에 대해서만 데이터를 수집하는 것이 아니라, 해당 유저의 다양한 정보들을 최대한 많이 가져오는 것으로 진행해 보라고 하셔서 유저의 모든 게시글, 댓글과 관련한 정보들을 스크래핑 해왔다. 이 데이터들을 DB에 저장하기 위해서 ERdiagram을 작성했고, 이에 맞추어 우리의 서버에서 저장할 수 있도록 했다.
[ ERDiagram 설계 ]
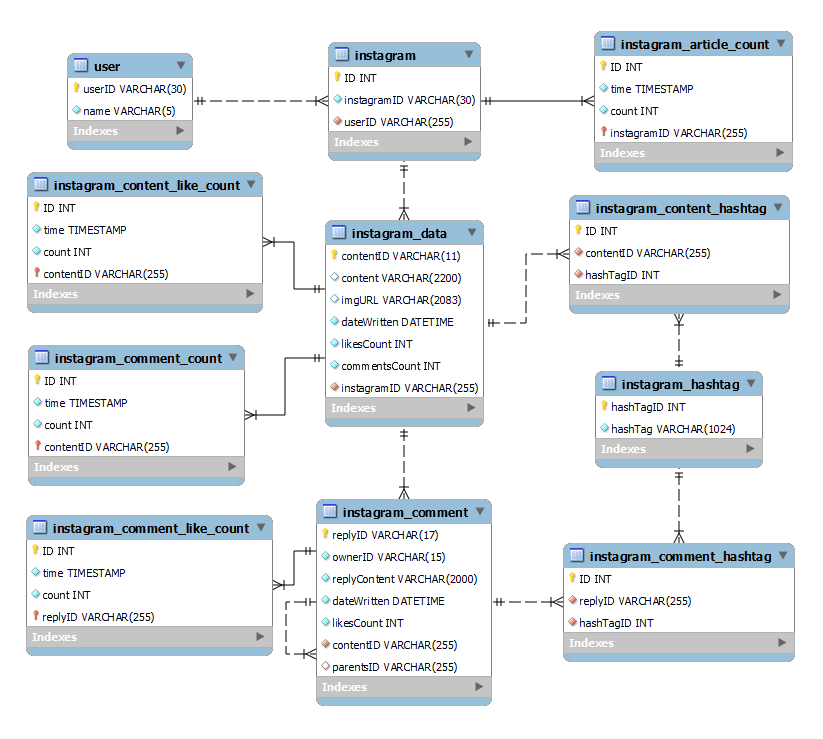
가장 기본적인 데이터에 해당하는 테이블은 4개가 있다. 우리 서비스의 유저와, 해당 유저의 인스타그램계정 정보, 게시글 정보, 댓글 정보를 저장하는 테이블이다. 각각 데이터에 대한 ID값을 키값으로 가지고 있지만 한 명의 유저가 여러 개의 인스타그램 계정을 보유할 수도 있기 때문에 instagram 테이블은 Auto Increment 속성을 가지는 정수형 ID를 키값으로 갖도록 설계했다.
instagram_[ ]_count에 해당하는 테이블은 게시글과 댓글에 따른 좋아요 수와 게시글의 개수, 게시글에 따른 댓글의 수의 추이를 저장하는 테이블이다. 변동 추이를 활용해서 데이터를 정형화할 수도 있기 때문이다. 원래 time과 count 컬럼을 이용해서 복합키로 설정하려고 했는데, Auto increment 속성을 가지는 기본 키를 설정했다. (사실 typeORM으로 entity를 선언하는데 타임스탬프 타입의 변수가 기본 키로 설정이 안되어서 우회했다 ?)
해시태그에 대해서는 이미 존재하는 해시태그가 계속 추가되지 않도록 하기 위해서 해시태그만 저장하는 테이블을 만들고, 게시글과 해시태그를 매칭하는 테이블, 댓글과 해시태그를 매칭하는 테이블을 만들었다. 원래는 instagram_content_hashtag와 instagram_comment_hashtag를 하나의 테이블에 넣고 게시물인지, 댓글인지를 구분해 주는 컬럼을 넣으려고 했으나 댓글과 게시글의 ID 값의 길이가 달라서 구분했다.
[ MySQL RDS ]
xuzy님과 함께 진행 중이기에 MySQL을 로컬로 사용할 수가 없었다. 따라서 AWS의 RDS를 활용해서 클라우드에서 DB를 운영하기로 했다. 한글 인코딩을 위해서 파라미터 그룹의 인코딩 관련 파라미터의 값을 UTR-8로 지정하고, 이 파라미터 그룹을 DB에 적용했다. 이후 접속 권한을 설정하기 위해 인바운드 규칙과 VPC 보안그룹 등을 설정하고 각각의 개념에 대해서 공부했다. 이후 우리의 프로젝트에서 이 RDS의 인스턴스에 접근해서 데이터를 저장할 수 있도록 했다.